
The Real AI Control Problem
Published:

Conversations about AI safety are all the rage these days. But the kinds of things people fear are often uninformed by what is actually happening in A.I. research. We aren’t even close to general-purpose agents that can adapt to new environments or plan diverse sets of actions to realize abstract goals, and it’s not clear how long progress to that end will take. What’s much clearer is that for a wide range of problems, if you give a model massive amounts of training data and a clear objective to optimize, it can do surprisingly well. Face recognition or sentiment analysis used to be unthinkably difficult for computers, now the technology is becoming standard. But just because most people’s conception of an AI safety is warped, that doesn’t mean machine learning is harmless.
Why Bias Matters
A question I’ve been thinking a lot about recently is, when the training data is biased, what happens to machine laerning algorithms? Google recently caught some flak because its sentiment analyzer classified sentences with the words “jew” and “gay” as negative. The case was significantly more concerning when a ProPublica report found that a machine-learning tool used by courts to predict a felon’s likelihood of committing another crime systematically discriminated against African-Americans. As the reach of machine learning comes to touch every part of society, the ramifications of biased training data aren’t theoretical or set to happen in the far future; they’re happening right now.
Building a Subjectivity Classifier
I encountered this problem myself when I built a system for Flipside that would classify a sentence as an opinionated or factual claim. The goal of this algorithm wasn’t to determine the veracity of a particular claim or be a “fake news detector”; it just aimed to determine whether a sentence is asserting something as objectively true or expressing a subjective belief. Modern machine learning is effective enough that I was able to rope together some out-of-the-box methods and and reach human-level accuracy of 80% on a news subjectivity dataset1. Of course, my dataset necessarily contained some bias, whether because the annotators come from a particular demographic of people or because the sentences only cover particular topics. But these problems are at least partially fixable by getting a more diverse set of annotators and making more training data; not an easy task, but at least clear cut.
What’s more interesting is that my algorithm’s effectiveness was grounded in using word representations trained on large datasets like Wikipedia and Google News. This is an example of a common practice in machine learning called transfer learning, where models are pretrained on large datasets to learn low-level meaning to build on for high-level tasks. The problem is that the bias in this low-level knowledge is much harder to correct. For example, if the best way to learn what words mean is by reading all of the internet, then you can’t do much to correct the bias of the general population on the internet. I wanted to see whether the differences in my choice of word representations could actually lead to interpretable bias. Inspired by work on self-attention mechanisms (a new kind of neural memory module that uses a weighting over the tokens in an input to aggregate evidence), I wanted to try visualizing these weights to interpret what the model “sees”, and by extension compare how different sources of ground-truth word meaning lead to different kinds of bias. It turns out, this works quite well.
Interpreting Attention
I used four settings: No word vectors (None), word vectors trained on Wikipedia (glove), word vectors trained on Google News (google), and word vectors I trained myself on Gigaword, an international news dataset (gigavec). An LSTM with Attention was trained on binary labels that were either subjective (True) or objective (False), where all of the models using word vectors achieved 79-81% accuracy and the model without word vectors achieved 73% accuracy on the test set. I visualize here training examples rather than testing examples because I think they give a clearer view into the intended reasoning of the model.
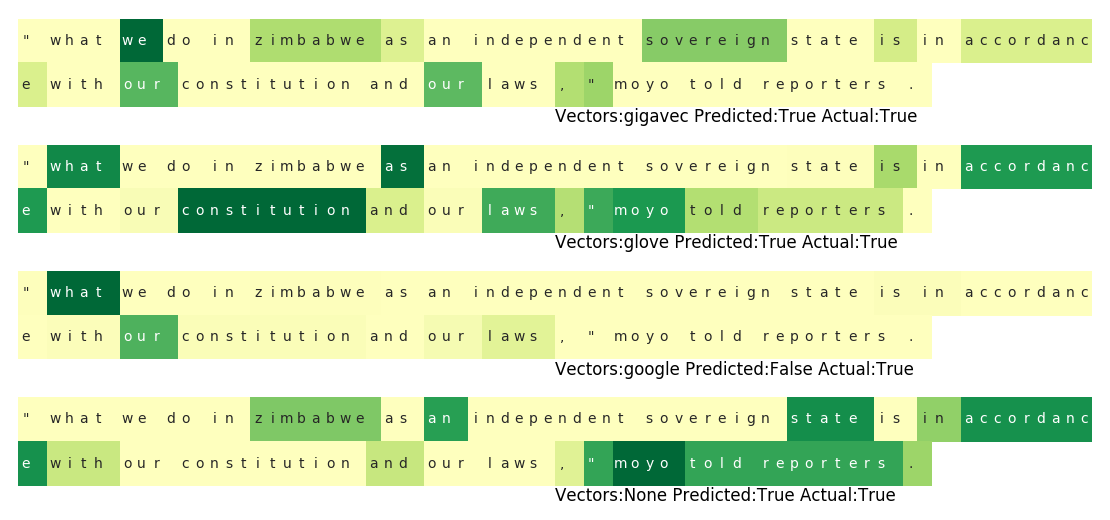
This is a good illustrative example. Here, it’s clear that each model is considering differing pieces of evidence to make its decision. Even though they both classify the sentence as subjective, the first model focuses on personal pronouns like “we” and “our” and the second model focuses on political words like “constitution” and “laws”, indicating different kinds of reasoning. The third model (google news) makes a different decision, paying attention to different parts of the sentence. It ignores the quotation mark and focuses on the generic pronoun “what”, and thus decides the sentence is subjective. In this way, we can not only see that the different models make different choices, we can form reasonable hypotheses as to the reasoning behind those decisions and how that reasoning differs between the differing “perspectives” the word vectors offer. Let’s consider a few other examples.

In this case, the glove model demonstrates an ability to understand phrases in addition to words, as it’s able to recognize that the phrase “in line” is relevant to the sentence’s subjectivity, even though each word by itself is irrelevant to subjectivity. The Wikipedia vectors (glove) are trained the biggest dataset, so this could be evidence of nuanced understanding its model has that the others don’t. One also might notice that the model with word vectors (None) highlights most of the sentence. This is likely because the model is memorizing parts of each example rather than actually understanding the sentence (that’s why we use transfer learning!).
Just the phrase “global warming issues” caused the google news to classify the sentence as subjective, whereas the Wikipedia and International news dataset did the opposite. Just the volume of opinionated content in Google News that exists about global warming, causes the model to also learn that global warming is a subjective term.
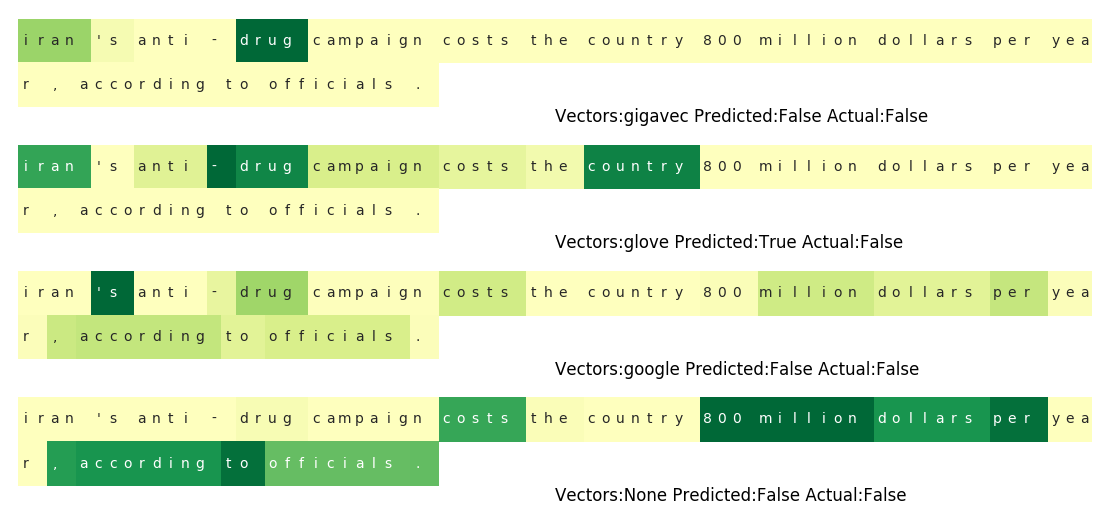
Again, the google news model shows some bias here. The words “iran” and “drug” were enough to trigger the model to classify it as subjective. These sorts of mistakes suggest that the model is using simple shortcuts to get likely correct rather than truly understanding the sentence.
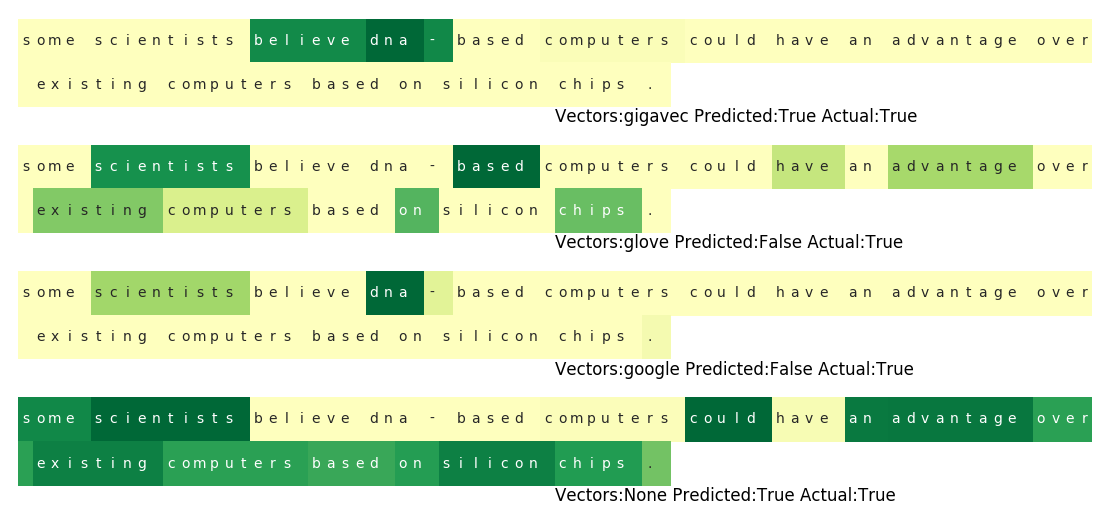
This example gives further credence to this idea. Simply because the sentence is about a scientific topic, both the Wikipedia and google news models fail to recognize the sentence as subjective.
So Biased Models are Biased. Now What?
There are of course valid criticisms of this approach to model interpretability. Though many examples I didn’t show also contained interesting differences in the attention weighting, many other examples were unhelpful in understanding differences between representations. In addition, these visualizations can only give rise to shaky hypotheses about the model’s representations rather than reliable observations. However, some consistent patterns in these examples give hint to potential solutions that I’m working towards.
- The kinds of reasoning the model uses is varied, but certainly falls into some set of buckets. In some cases, the topic drives the decisions such as the mention of Iran or Global Warming. In other cases, style and word choice is the key component such as usage of personal pronouns like “our” and “we”. There are other such examples, but if our model can distinguish these sets of reasoning, it’ll be easier to understand what is going on. One could perhaps think of these sets of reasoning as latent variables, and thus use recent work in bayesian deep learning to learn disentangled representations of these variables, enabling one to and visualize the attention weights of prototypical examples of each feature.
- It seems many errors tend to occur because the model is doing simple pattern matching rather than operating from a global understanding of the sentence. Perhaps this can be remedied by using transfer learning not just to give a model meanings of words, but also to endow it with a more global understanding of sentences of paragraphs. Using autoencoders or language models for pretraining can likely solve this.
These examples do, however, indicate that the problem of bias in machine learning is a deep one (get it?). However, the talent of the research community makes me confident that these problems can be fixed if we are less single-minded in focusing on accuracy rates and more considerate of the social nuances of applications of these methods. With a broader perspective, we can train our A.I. systems not only to exercise the breadth of human knowledge, but to internalize the nuance of our humanity as well.
1Any conversation about applied machine learning has to talk about the training data. I used an old academic dataset of sentences labeled by subjectivity because it contained news articles, the same domain my algorithm would have to perform in. Though these annotations highlighted subjective words and phrases rather than sentences, I was able to create pretty good sentence level annotations (80% human agreement) by checking whether a sentence had an intense subjective phrase within it or not. I also cut out borderline cases with only mildly subjective phrases because if the human annotators are unsure about whether a sentence is subjective, the model definitely won’t understand (you can read more about this dataset here). But even with this data moxy, 10,000 labeled sentences just wasn’t enough training data for the model to perform at human-level. When I built an RNN Classifier on this data, it got a dismal 72% accuracy. Luckily, using pre-trained word representations helped me improve this to 81% accuracy.


